В двух предыдущих частях мы познакомились с устройством процессора и с тем, каким образом он выполняет адресованные ему команды. Однако если бы все было бы так просто…
Вспомним этапы выполнения:
1) выборка команды;
2) декодирование команды;
3) выборка операндов;
4) выполнение команды;
5) сохранение результата.
Все они выполняются последовательно, друг за другом. Причем информация постепенно переходит с одного этапа на другой. Можно привести в качестве примера работу прачечной. Для того, чтобы постирать белье, надо пройти 3 шага: собственно постирать белье (40 мин.), затем просушить (60 мин.) и поутюжить (30 мин).
Теперь предположим, что трём девушкам – Кате, Маше и Тане – надо обратиться в эту службу для стирки белья. Они идут втроем в одну и ту же прачечную. Каждая девушка по очереди выполняет все операции. Согласно рисунку 1, девушкам потребуется 390 минут (6,5 часов) для того, чтобы закончить свою большую стирку.

Рисунок 1
Попробуем оптимизировать процесс стирки. Каждая девушка будет приступать к своей очередной операции сразу же после того, как предыдущая девушка закончит эту же операцию и освободит соответствующее оборудование.

Рисунок 2
Как видно из рисунка 2, девушки справятся за 250 минут либо чуть больше, чем 4 часа. Это позволило девушкам сократить время примерно на треть. Такой подход называется конвейеризацией.
Такая же ситуация получается и с выполнением команд процессором. Только в этом случае вместо минут будут использоваться машинные такты (вспомните, что блок синхронизации как раз отвечает за генерацию тактов).
Обратим внимание, что, если этапы разной длины, то для того, чтобы начать следующую операцию, приходится ждать, пока освободится оборудование (в нашем случае сушилка), и бездействовать. В приведенном примере можно еще более оптимизировать процесс. Тогда Маша и Таня начнут стирку так, чтобы она закончилась именно тогда, когда освободится сушилка. Таким образом, у нас не будет простоя в середине. И выглядеть будет, как показано на рисунке 3.
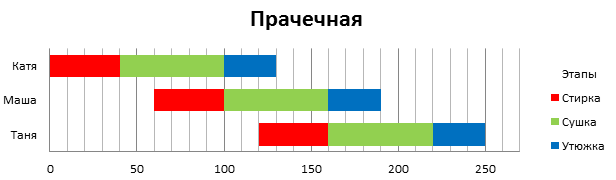
Рисунок 3
В конечном итоге нам удалось добиться сокращения выполнения всей большой стирки девушек, при этом каждая из них проведет в прачечной минимальное количество времени. Однако это не всегда возможно, и порой оказывается, что общая длительность каждой команды по отдельности увеличивается (как это получилось на рисунке 2), но общее время выполнения сокращается в любом случае.
В ситуации с центральным процессором все еще сложнее. Дело в том, что в одно и то же время разным стадиям конвейера может понадобиться обратиться к памяти, например, для загрузки операндов из памяти одной команде и сохранения результата в память другой. Или еще, например, когда одной команде требуются данные, которые ещё считаются предыдущей командой. В этом случае самым простым, но наименее эффективным способом будет вставка команды ожидания. Эта команда называется nop (сокращенно от слов no operation). Еще одним способом борьбы с такими трудностями является переупорядочивание команд (на этапе компиляции программы команды переставляются таким образом, чтобы минимально зависеть от соседних). Также применяются некоторые архитектурные решения, например, имеется возможность протолкнуть результат напрямую из АЛУ в следующую команду, ожидающую данных, чтобы та могла начать вычисление, пока результат будет сохраняться в регистр или в оперативную память.
Таким образом, конвейеризация вычислений дает существенный прирост производительности, однако в то же время существенно усложняет архитектуру ЦП. Кроме того, с появлением конвейера возникают дополнительные проблемы. О них мы поговорим подробно в следующей части.
Пацовский Игорь
Effective Soft, Ltd.






















