Искусственный интеллект врывается в нашу жизнь. В будущем, наверное, все будет классно, но пока возникают кое-какие вопросы, и все чаще эти вопросы затрагивают аспекты морали и этики. Какие сюрпризы преподносит нам машинное обучение уже сейчас? Можно ли обмануть машинное обучение, а если да, то насколько это сложно? И не закончится ли все это Скайнетом и восстанием машин? Давайте разберемся.
Разновидности искусственного интеллекта: Сильный и Слабый ИИ
Для начала стоит определиться с понятиями. Есть две разные вещи: Сильный и Слабый ИИ. Сильный ИИ (true, general, настоящий) — это гипотетическая машина, способная мыслить и осознавать себя, решать не только узкоспециализированные задачи, но еще и учиться чему-то новому.
Слабый ИИ (narrow, поверхностный) — это уже существующие программы для решения вполне определенных задач: распознавания изображений, управления автомобилем, игры в Го и так далее. Чтобы не путаться и никого не вводить в заблуждение, Слабый ИИ обычно называют «машинным обучением» (machine learning).
Про Сильный ИИ еще неизвестно, будет ли он вообще изобретен. Судя по результатам опроса экспертов, ждать еще лет 45. Правда, прогнозы на десятки лет вперед — дело неблагодарное. Это по сути означает «когда-нибудь». Например, рентабельную энергию термоядерного синтеза тоже прогнозируют через 40 лет — и точно такой же прогноз давали и 50 лет назад, когда ее только начали изучать.
Машинное обучение: что может пойти не так?
Если Сильного ИИ ждать еще непонятно сколько, то Слабый ИИ уже с нами и вовсю работает во многих областях народного хозяйства.
И таких областей с каждым годом становится все больше и больше. Машинное обучение позволяет решать практические задачи без явного программирования, а путем обучения по прецедентам.
Поскольку мы учим машину решать конкретную задачу, то полученная математическая модель — так называется «обученный» алгоритм — не может внезапно захотеть поработить (или спасти) человечество. Так что со Слабым ИИ никакие Скайнеты, по идее, нам не грозят: алгоритм будет прилежно делать то, о чем его попросили, а ничего другого он все равно не умеет. Но все-таки кое-что может пойти не так.
1. Плохие намерения
Начать с того, что сама решаемая задача может быть недостаточно этичной. Например, если мы при помощи машинного обучения учим армию дронов убивать людей, результаты могут быть несколько неожиданными.
Как раз недавно по этому поводу разгорелся небольшой скандал. Компания Google разрабатывает программное обеспечение, используемое для пилотного военного проекта Project Maven по управлению дронами. Предположительно, в будущем это может привести к созданию полностью автономного оружия.
Так вот, минимум 12 сотрудников Google уволились в знак протеста, еще 4000 подписали петицию с просьбой отказаться от контракта с военными. Более 1000 видных ученых в области ИИ, этики и информационных технологий написали открытое письмо с просьбой к Google прекратить работы над проектом и поддержать международный договор по запрету автономного оружия.
2. Предвзятость разработчиков алгоритма
Даже если авторы алгоритма машинного обучения не хотят приносить вред, чаще всего они все-таки хотят извлечь выгоду. Иными словами, далеко не все алгоритмы работают на благо общества, очень многие работают на благо своих создателей. Это часто можно наблюдать в области медицины — важнее не вылечить, а порекомендовать лечение подороже.
На самом деле иногда и само общество не заинтересовано в том, чтобы полученный алгоритм был образцом морали. Например, есть компромисс между скоростью движения транспорта и смертностью на дорогах. Можно запрограммировать беспилотные автомобили так, чтобы они ездили со скоростью не более 20 км/ч. Это позволило бы практически гарантированно свести количество смертей к нулю, но жить в больших городах стало бы затруднительно.
3. Параметры системы могут не включать этику
По умолчанию компьютеры не имеют никакого представления о том, что такое этика. Представьте, что мы просим алгоритм сверстать бюджет страны с целью «максимизировать ВВП / производительность труда / продолжительность жизни» и забыли заложить в модель этические ограничения. Алгоритм может прийти к выводу, что выделять деньги на детские дома / хосписы / защиту окружающей среды совершенно незачем, ведь это не увеличит ВВП — по крайней мере, прямо.
И хорошо, если алгоритму поручили только составление бюджета. Потому что при более широкой постановке задачи может выйти, что самый выгодный способ повысить среднюю производительность труда — это избавиться от всего неработоспособного населения.
Выходит, что этические вопросы должны быть среди целей системы изначально.
4. Этику сложно описать формально
С этикой одна проблема — ее сложно формализовать. Во-первых, этика довольно быстро меняется со временем. Например, по таким вопросам, как права ЛГБТ и межрасовые / межкастовые браки, мнение может существенно измениться за десятилетия.
Во-вторых, этика отнюдь не универсальна: она отличается даже в разных группах населения одной страны, не говоря уже о разных странах. Например, в Китае контроль за перемещением граждан при помощи камер наружного наблюдения и распознавания лиц считается нормой. В других странах отношение к этому вопросу может быть иным и зависеть от обстановки.
Также этика может зависеть от политического климата. Например, борьба с терроризмом заметно изменила во многих странах представление о том, что этично, а что не очень — и произошло это невероятно быстро.
5. Машинное обучение влияет на людей
Представьте систему на базе машинного обучения, которая советует вам, какой фильм посмотреть. На основе ваших оценок другим фильмам и путем сопоставления ваших вкусов со вкусами других пользователей система может довольно надежно порекомендовать фильм, который вам очень понравится.
Но при этом система будет со временем менять ваши вкусы и делать их более узкими. Без системы вы бы время от времени смотрели и плохие фильмы, и фильмы непривычных жанров. А так, что ни фильм — то в точку. В итоге вы перестаете быть «экспертами по фильмам», а становитесь только потребителем того, что дают.
Интересно еще и то, что мы даже не замечаем, как алгоритмы нами манипулируют. Пример с фильмами не очень страшный, но попробуйте подставить в него слова «новости» и «пропаганда»…
6. Ложные корреляции
Ложная корреляция — это когда не зависящие друг от друга вещи ведут себя очень похоже, из-за чего может возникнуть впечатление, что они как-то связаны. Например, потребление маргарина в США явно зависит от количества разводов в штате Мэн, не может же статистика ошибаться, правда?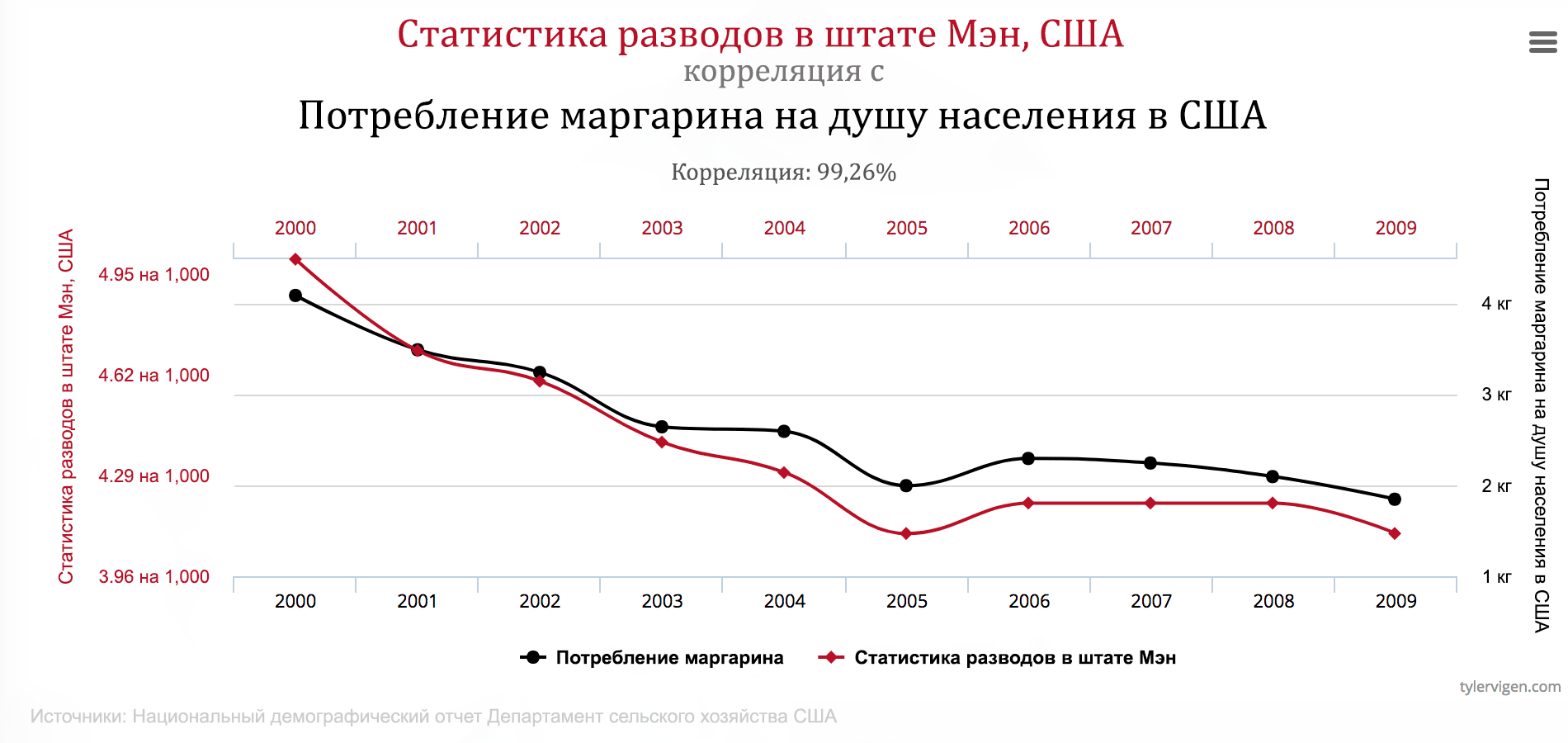
Конечно, живые люди на основе своего богатого жизненного опыта подозревают, что маргарин и разводы вряд ли связаны напрямую. А вот математической модели об этом знать неоткуда, она просто заучивает и обобщает данные.
Известный пример: программа, которая расставляла больных в очередь по срочности оказания помощи, пришла к выводу, что астматикам с пневмонией помощь нужна меньше, чем людям с пневмонией без астмы. Программа посмотрела на статистику и пришла к выводу, что астматики не умирают, поэтому приоритет им незачем. А на самом деле такие больные не умирали потому, что тут же получали лучшую помощь в медицинских учреждениях в связи с очень большим риском.
7. Петли обратной связи
Хуже ложных корреляций только петли обратной связи. Это когда решения алгоритма влияют на реальность, что, в свою очередь, еще больше убеждает алгоритм в его точке зрения.
Например, программа предупреждения преступности в Калифорнии предлагала отправлять больше полицейских в черные кварталы, основываясь на уровне преступности — количестве зафиксированных преступлений. А чем больше полицейских машин в квартале, тем чаще жители сообщают о преступлениях (просто есть кому сообщить), чаще сами полицейские замечают правонарушения, больше составляется протоколов и отчетов, — в итоге формально уровень преступности возрастает. Значит, надо отправить еще больше полицейских, и далее по нарастающей.
8. «Грязные» и «отравленные» исходные данные
Результат обучения алгоритма сильно зависит от исходных данных, на основе которых ведется обучение. Данные могут оказаться плохими, искаженными — это может происходить как случайно, так и по злому умыслу (в последнем случае это обычно называют «отравлением»).
Вот пример неумышленных проблем с исходными данными: если в качестве обучающей выборки для алгоритма по найму сотрудников использовать данные, полученные из компании с расистскими практиками набора персонала, то алгоритм тоже будет с расистским уклоном.
В Microsoft однажды учили чат-бота общаться в Twitter’е, для чего предоставили возможность побеседовать с ним всем желающим. Лавочку пришлось прикрыть менее чем через сутки, потому что набежали добрые интернет-пользователи и быстро обучили бота материться и цитировать «Майн Кампф».
Пример умышленного отравления машинного обучения: в лаборатории по анализу компьютерных вирусов математическая модель ежедневно обрабатывает в среднем около миллиона файлов, как чистых, так и вредоносных. Ландшафт угроз постоянно меняется, поэтому изменения в модели в виде обновлений антивирусных баз доставляются в антивирусные продукты на стороне пользователей.
Злоумышленник может постоянно генерировать вредоносные файлы, очень похожие на какой-то чистый, и отправлять их в лабораторию. Граница между чистыми и вредоносными файлами будет постепенно стираться, модель будет «деградировать». И в итоге модель может признать оригинальный чистый файл зловредом — получится ложное срабатывание.
9. Взлом машинного обучения
Отравление — это воздействие на процесс обучения. Но обмануть можно и уже готовую, исправно работающую математическую модель, если знать, как она устроена. Например, группе исследователей удалось научиться обманывать алгоритм распознавания лиц с помощью специальных очков, вносящих минимальные изменения в картинку и тем самым кардинально меняющих результат.
Даже там, где, казалось бы, нет ничего сложного, машину легко обмануть неведомым для непосвященного способом.

Первые три знака распознаются как «Ограничение скорости 45», а последний — как знак «STOP»
Причем для того, чтобы математическая модель машинного обучения признала капитуляцию, необязательно вносить существенные изменения — достаточно минимальных, невидимых человеку правок.

Если к панде слева добавить минимальный специальный шум, то получим гиббона с потрясающей уверенностью
Пока человек умнее большинства алгоритмов, он может обманывать их. Представьте себе, что в недалеком будущем машинное обучение будет анализировать рентгеновские снимки чемоданов в аэропорту и искать оружие. Умный террорист сможет положить рядом с пистолетом фигуру особенной формы и тем самым «нейтрализовать» пистолет.
Кто виноват и что делать
В 2016 году Рабочая группа по технологиям больших данных при администрации Обамы выпустила отчет, предупреждающий о том, что в алгоритмы, принимающие автоматизированные решения на программном уровне, может быть заложена дискриминация. Также в отчете содержался призыв создавать алгоритмы, следующие принципу равных возможностей.
Но сказать-то легко, а что же делать? С этим не все так просто.
Во-первых, математические модели машинного обучения тяжело тестировать и подправлять. Если обычные программы мы читаем по шагам и научились их тестировать, то в случае машинного обучения все зависит от размера контрольной выборки, и она не может быть бесконечной.
К примеру, приложение Google Photo распознавало и помечало людей с черным цветом кожи как горилл. И как быть? За три года Google не смогли придумать ничего лучше, чем запретить помечать вообще любые объекты на фотографиях как гориллу, шимпанзе и обезьяну, чтобы не допускать повторения ошибки.
Во-вторых, нам сложно понять и объяснить решения машинного обучения. Например, нейронная сеть как-то расставила внутри себя весовые коэффициенты, чтобы получались правильные ответы. А почему они получаются именно такими и что сделать, чтобы ответ поменялся?
Исследование 2015 года показало, что женщины гораздо реже, чем мужчины, видят рекламу высокооплачиваемых должностей, которую показывает Google AdSense. Сервис доставки в тот же день от Amazon зачастую недоступен в черных кварталах. В обоих случаях представители компаний затруднились объяснить такие решения алгоритмов.
Винить вроде бы некого, остается принимать законы и постулировать «этические законы робототехники». В Германии как раз недавно, в мае 2018 года, сделали первый шаг в этом направлении и выпустили свод этических правил для беспилотных автомобилей. Среди прочего, в нем есть такие пункты:
- Безопасность людей — наивысший приоритет по сравнению с уроном животным или собственности.
- В случае неизбежной аварии не должно быть никакой дискриминации, ни по каким факторам недопустимо различать людей.
Но что особенно важно в нашем контексте:
- Автоматические системы вождения становятся этическим императивом, если системы вызывают меньше аварий, чем водители-люди.
Очевидно, что мы будем все больше и больше полагаться на машинное обучение — просто потому, что оно в целом будет справляться со многими задачами лучше людей. Поэтому важно помнить о недостатках и возможных проблемах, стараться все предусмотреть на этапе разработки систем — и не забывать присматривать за результатом работы алгоритмов на случай, если что-то все же пойдет не так.




















Комментарии
Страницы
Жизнедеятельность технологической цивилизации, ее развитие, происходит в двух принципиально различных информационных средах: 1. В сфере строгих, относительно хорошо формализуемых и формализованных дисциплин – технологий, и 2. В сфере объективно очень плохо формализуемых, а потому и неформализованных дисциплин – гуманитарных ("философий"). И хоть головой об стенку, но благополучие людей определяется решениями гуманитарных вопросов, а технологические вопросы важны лишь постольку, поскольку помогают, или мешают, решать гуманитарные. Разумеется, существуют и мощные обратные связи, технологии образуют материальные возможности (фон для решения гуманитарных вопросов). Но технологии, сами по себе, не умеют решать гуманитарные вопросы вовсе. И не претендуют на это. Новые материальные ресурсы для продолжения развития технологий, технологии просят предоставить гуманитарные образования. Последние координируют и распределяют ресурсы, ранее безропотно предоставленные им технологиями. Потому что даже выдающиеся технари – самые обыкновенные млекожующие люди, которые жаждут именно гуманитарных благ, и как все нормальные люди вовсе не ожидают получить их непосредственно из технологий. Электричеством единым сыт не будешь© (Alt+0169)
Это банальные истины, но похоже некоторым они неизвестны.
Лучшее, что может делать технология - помогать "философии" решать гуманитарные (целеполагающие) вопросы. Для этого желательно иметь о них представление. В противном случае (по глупости и невежеству), творить зло.
Питон, философия в узком смысле -- область воззрений об отношении бытия и сознания, в широком -- любовь к размышлениям, а вовсе не "наука" об общих законах, как любят говорить материалисты-марксисты. Именно поэтому на Западе нет понятия "доктор таких-то наук", а есть понятие "доктор философии". Поэтому всё, что не формализуется (а т.ч. и парадокс Ферми) -- область философии. В широком смысле. А не "вопрос техники".
Михаил, технологии -- не фон, п способ решения гуманитарных вопросов.
Большинство людей -- нахлебники небольшого количества людей, продвигающих технологии. Беда в том, что мы недалеко ушли от животных. И основной массе ничего более не надо, чем жрать, доминировать и размножаться. Инстинкт познания у большинства находится в загоне. Пример? Вот какой материал будут больше посещать: о сжатии данных или о "сымай трусы"?
Ну-ну. Накормите людей без технологий.
К чему ведёт отсутствие технологий -- видим на примере африканских "беженцев", наводняющих Европу. На самом деле им, видите ли, "кушать хоцца".
Да, рекомендую почитать Авдеева "Расология". :)
Возвращаясь к сабжу. В копипасте слабомыслящего репостера (слабомыслящего, т.к. излагает не свои мысли) имхо неверно даётся определение сильного ИИ:
Сразу возникают вопросы: что такое "мыслить"? (высшие млекопитающие разве не мыслят?), что есть "осознание себя" ? (муха осознаёт себя, раз выделяет себя из окружения и избегает смерти?), что значит "учиться новому"? (комп, запоминая лучший эвристический алгоритм, разве не учится "чему-то новому"?).
Всё проще. Сильный ИИ в отличие от слабого способен не только решать, но и ставить задачи.
Хм. То есть для сильного ИИ "ставить задачи" - это означает "решать задачу" на порождение новых задач?
Если под задачей подразумевать функцию, то это не проблема. Поди.
Задача -> "Накормить человека " - порождение новых задач -> сходить в лес за хворостом, заказать мясо в Евроопте, разжечь камин ...
Логик, это ты писал в "вики" раздельчик "постановка задачи"? :)
Нет, но написано согласно ГОСТУ поди. (С)
Вы меня шантажируете?))) Зеркально:
Где были бы "ваши" технологии, если бы остались без гуманитарной инфраструктуры (общественных устройств – систем управления социумами)? А их бы просто не было. А прокорм ... вполне реально безо всяких технологий, как находят себе пропитание все животные – в лесах, полях, пещерах... Когда-то так и было ...
А если по существу, то вы передергиваете. – Я нигде не произносил глупость, что технологии, – это неважно. В отличии от некоторых по поводу "философии"...
Причина вовсе не отсутствие технологий. Есть они есть, значит есть. А неумение, или неспособность, или недоступность, или злой умысел, не позволяющие их использовать. А это все самые что ни есть, гуманитарные проблемы ... Не так?
Страницы