Свои представления вместо чужих, путь первый: схема экрана есть схема данных
Сегодня организации не принимают решения в пользу собственной разработки ПО, т.к. чиновник зачастую хочет чуда сегодня, он не готов ждать, а приобретение продукта сторонних фирм практически всегда оборачивается уже известными проблемами: стоимость настройки ПО превышает стоимость собственной разработки, часть бизнес-процессов не автоматизируется предоставленным ПО или стоимость автоматизации слишком велика и проще использовать старые разрозненные программы предыдущего поколения. Выходом из сложившейся ситуации могла бы стать технология быстрого написания, излагаемая ниже.
Сложность схемы базы данных и запутанность настроек программы, созданной для этой базы, примерно одинаковы. Однако всегда сложнее понять чужие мысли, чем изложить свои собственные самому себе. Поэтому вы создадите схему базы-для-себя быстрее, чем представите карту взаимосвязей чужих настроек. И если бы на весах лежали только схема и карта, понятно, что бы вы предпочли.
Что же заставляет нас выбирать плохое решение да ещё и платить за него? Какую третью гирю мы должны сбросить с первой чаши, чтобы обрести сразу двойную выгоду? Мы должны сбросить программирование - или редуцировать его в максимальной степени.
Это возможно, если обратить внимание на одну тонкость - поля вывода связаны отношениями IDEF1. Экран программы имеет схему, и эта схема полностью повторяет схему базы данных!
Например, если мы выводим сотрудников какого-либо департамента (рис. 1), то получившаяся иерархия является калькой с отношений базы данных (рис. 2).
 |
| Рис. 1 |
 |
| Рис. 2 |
Здесь есть вторая тонкость - синтаксис, выражающий иерархию, например, "Departments.Persons" напрочь отсутствует в SQL. В соединениях таблиц (декартовых произведениях) клиент не может разделить, какие поля относятся к одной таблице, какие - к другой. Получается, что, извлекая информацию из базы данных, мы теряем какую-то её часть!
Вместо того чтобы вставить теряемую информацию машиной, мы пытаемся сделать это вручную, заставляя человека трассировать работу компьютера. На это уходит до 50% рабочего времени. Трассировка записывается в нотации LOOP/FETCH. Мы извлекаем по одной записи для того, чтобы найти связанные с нею. И эта проблема до сих пор не отрефлексирована индустрией.
Сильное решение есть. Это выражения вида "SELECT * FROM Departments.Persons" для извлечения записей, уже связанных внешним ключом. Департаменты и персоны могут быть даже связаны не напрямую, а через таблицу-посредник, например, таблицу "Sections" - тогда упомянутый запрос будет выглядеть так:
select Departments.Persons from Departments.Sections.Persons where Departments/@name="E-banking";
Если обе таблицы ссылаются друг на друга или одна ссылается на другую несколькими внешними ключами, то эта неоднозначность разрешается в запросе дерева: после, собственно, имени таблицы, содержащей нужный внешний ключ, ставится знак '#' и имя нужного ссылающегося поля (не имя constraint-а, т.е. внешнего ключа). Выглядит как новое имя таблицы с символом '#' в середине имени. Такое указание имени ссылающегося поля будем называть термином 'рафинирование'. Например, если "последующая" таблица ссылается на "предыдущую" (рис. 3), то запрос выглядит следующим образом:
select * from a.b#ref1.c#lnk1;
 |
| Рис. 3 |
и возвращает (для того, чтобы представить иерархические данные, мы должны использовать хоть какой-то формат. Для удобства визуального представления будем применять XML. Внешние ключи, использованные при построении ответа, не должны выводиться1)
<a id=1 data=12.3> <b#ref1 id=10 ref2=2 data=34.5> <c#lnk1 id=100 lnk2=20 data=78.9/> <c#lnk1 id=101 lnk2=20 data=89.1/> </b> <b#ref1 id=30 ref2=2 data=56.7> <c#lnk1 id=200 lnk2=40 data=91.2/> <c#lnk1 id=201 lnk2=40 data=88.8/> </b> </a>
Другой вариант ссылки одной таблицы на другую несколькими внешними ключами состоит в том, что "предыдущая" таблица ссылается на "последующую" (рис. 4) и требует запроса вида
select * from a#ref1.b#lnk1.c;
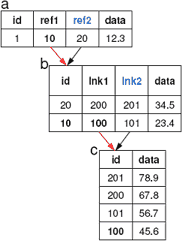 |
| Рис. 4 |
и возвращает
<a#ref1 id=1 ref2=20 data=12.3> <b#lnk1 id=10 lnk2=101 data=23.4> <c id=100 data=45.6/> </b> </a>
Аналогично, если таблица содержит список и ссылается на саму себя несколькими внешними ключами, то эта неоднозначность также разрешается в запросе дерева: после, собственно, имени таблицы ставится знак '$' и имя нужного ссылающегося поля (не имя constraint-а, т.е. внешнего ключа). Это также выглядит как новое имя таблицы с символом '$' в середине имени (рис. 5).
 |
| Рис. 5 |
Такое указание имени ссылающегося поля также будем называть термином 'рафинирование'. Запрос для дерева выглядит так2:
select * from a.b$ref1.c$ref3;
и возвращает
<a id=88 data=77.7> <b$ref1 id=1 ref2=20 data=12.3> <c$ref3 id=3 ref4=70 data=3.1/> <c$ref3 id=30 ref4=700 data=3.2/> <c$ref3 id=300 data=3.3/> </b> <b$ref1 id=10 ref2=200 data=23.4> <c$ref3 id=4 ref4=80 data=4.1/> <c$ref3 id=40 ref4=800 data=4.2/> <c$ref3 id=400 data=4.3/> </b> </a>
В тот момент, когда мы сможем отразить схему базы данных на схему экрана, минуя ручную трассировку, мы сможем писать личное ПО. Развитие этой идеи представлено в разделе "Hierarchical data output" отдельной презентации3. Автор заинтересован во мнениях, комментариях и возможной реализации этих предложений. Все предложения являются общественным достоянием.
Дмитрий ТЮРИН,
главный специалист департамента
ЦАБС "АСБ Беларусбанк",
член группы внедрения SAP R/3
1 Как вы заметили, возвращаемые данные в имени открывающего xml-тега содержат дополнительную информацию, необходимую для того, чтобы без всякого программирования вставить эти данные в базу данных. Эта дополнительная информация выглядит как новое имя открывающего тега с символом '#' в середине имени. Указание имени ссылающегося поля в теге будем называть термином "детерминация".
2 В двух разных видах рафинирования использованы разные знаки - '#' и '$' - чтобы оба вида рафинирования можно было использовать одновременно: 'table#field1$field2'.
3 Слайды # 3-62 презентации sql50.euro.ru/sql5.17.0.pdf














Комментарии
Это материал разработчика 3-го курса БГУИР и то отсталого.
Не описана методология создания софта. Задача не поставлена конкретно. Тоже самое я вижу в работах студентов.
Думаю наши студенты (БГУИР) после окончания ВУЗа утёрли бы нос данному господину.
Или в БГУИР за последние 5 лет нечто кардинально изменилось?
P.S. Учат(учили) по идее неплохо, счас БД важнее всех, пойму, что сейчас нормально учат (у нас было пару семестров с несложным "тестом на вменяемость в данной области" в результате). Много ли народу выучили ВСЕМУ? Куда троечников деваете нынче?
http://blogs.ingres.com/technology/2008/07/31/bringing-dbms-in-line-with-modern-communication-requirements-sql2009/
>Думаю наши студенты (БГУИР) после окончания ВУЗа утёрли бы нос данному господину
Чуть было не забыл - утрите, пожалуйста, реализуйте в какой-н free-шной СУБД - Postgres, MySQL, etc.
Хотя бы частично, я для вас даже задания на семестровый зачет нарисовал:
http://sql50.euro.ru/site/sql50/ru/ticket_ru.txt
А то все приходится то с фирмой http://enterprisedb.com/ переписываться, то еще с кем.
P.S.
Savely wrote:
> Учат(учили) по идее неплохо
Отвратительно учат, причем везде - и в Питере, и в Москве, и в Новосибирске: наберите SQL50 в Google. Интересовались преподаватели, да студенты не тянут, даже свои (их) собственные.
> у нас было пару семестров с __несложным__ "тестом на __вменяемость__ в данной области" в результате
:)
Или теперь есть специальность типа "программист БД"?